This commit reduces the total wall clock duration forsweep consesexecution by approximately 50%. It does so by reducing branch mispredictions from dereferencing storage blocks while sweeping the cons blocks. Parsing the output from some subprocesses such as LSP servers creates huge amounts of conses, so this commit is significant for increasing the responsiveness for modes such as eglot or company-mode.
I have only tested this on Mac OS on a processor with a 256 KB L2 cache. I am uncertain if the behavior is the same on other operating systems. There also may be constraints of which I'm unaware that make this not backwards compatible with other setups.
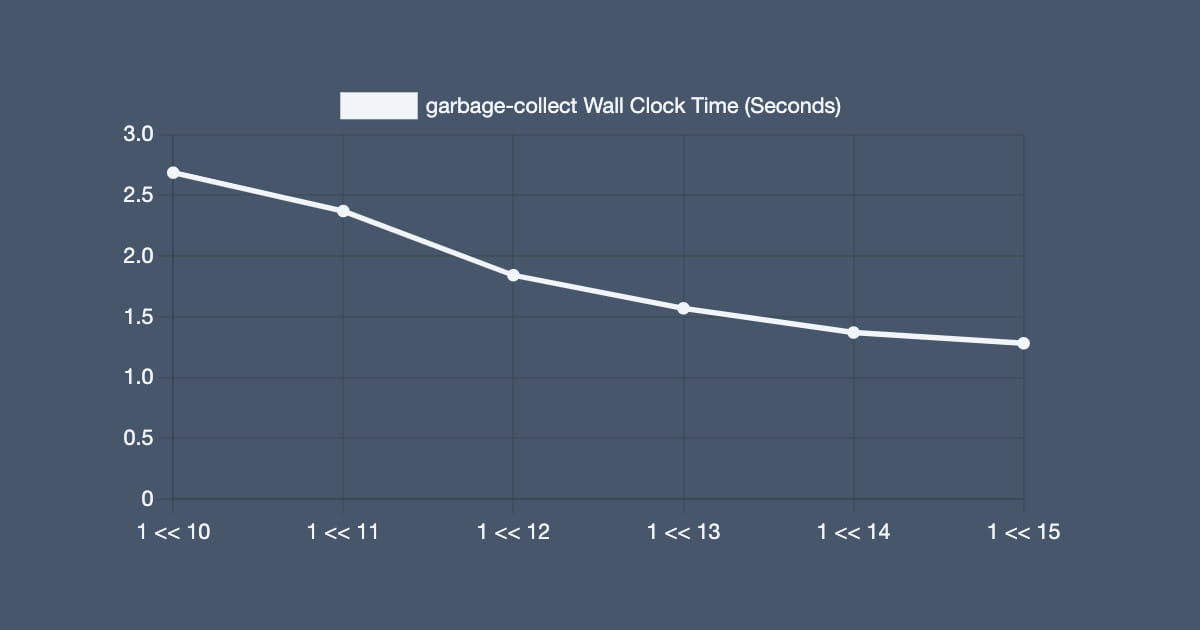
This commit changes BLOCK ALIGN from 1 << 10 to 1 << 15.
I ran the following program that creates a long chain of conses, and then nils them out to ensure that they get collected in the next call to garbage-collect. The total was arbitrarily picked. The experiment is repeatable, but the results are prone to noise. The effect is large enough to be visible even with these inconsistencies.
- (defun test-garbage-collect-large-cons-allocation ()
- (garbage-collect)
- (setq long-chain (cl-loop for i from 0 below
- 105910837 collect i))
- (garbage-collect)
- (redisplay)
- (message "%S" (garbage-collect))
- (setq gc-cons-threshold most-positive-fixnum)
- (let ((head long-chain))
- (while head
- (let ((tail (cdr head)))
- (setcdr head nil)
- (setcar head nil)
- (setq head tail))))
- (setq long-chain nil)
- (sleep-for 10)
- (let ((start-time (time-to-seconds (current-time))))
- (message "Start Garbage Collection")
- (setq gc-cons-threshold (car (get 'gc-cons-threshold 'standard-value)))
- (message "%S" (garbage-collect))
- (let ((duration (- (time-to-seconds (current-time)) start-time)))
- (prog1 duration (message "Garbage Collection: %f" duration)))))
The above graph shows that latency decreases whenBLOCK ALIGNincreases. It stops at 1 << 15 because my instance of emacs crashes on startup at that value.
Insweep conses, emacs traverses the cblock linked list. With the current value for BLOCK ALIGN, each block contains less than 1024 conses. Since there are no guarantees of cache locality between blocks, each dereference is a branch misprediction. By increasing the size of these blocks, the total amount of work is decreased from having less total blocks, because there are less branch mispredictions total.
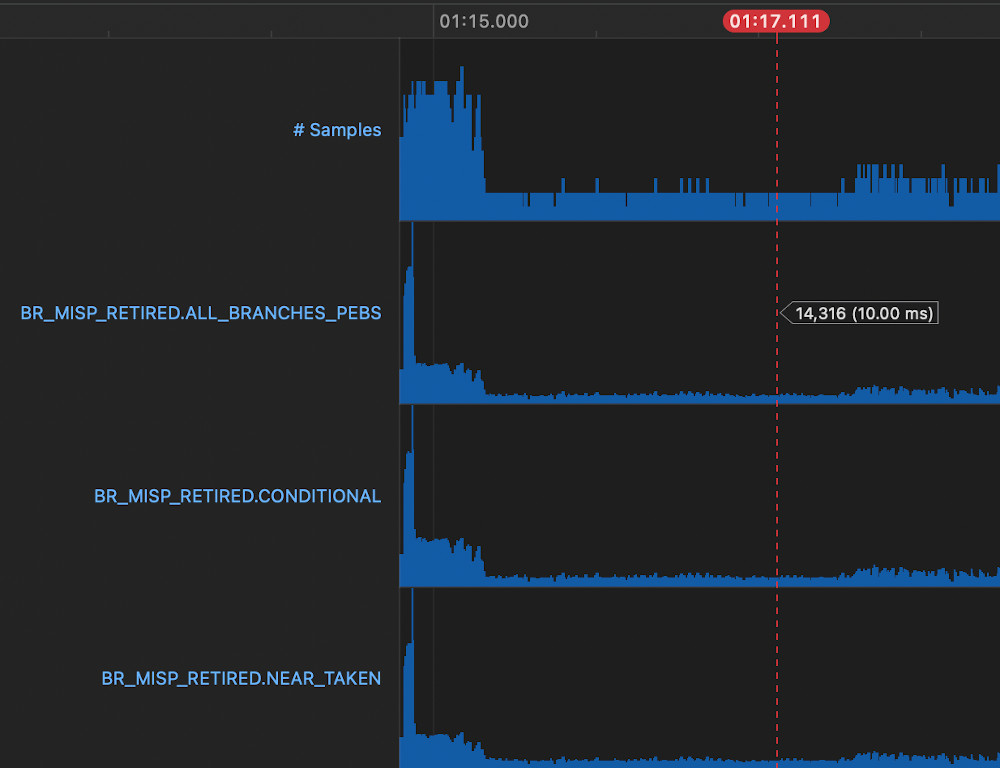
Picking a representative sample from a run without the change using Instruments.app's performance counter view shows 14316 branch mispredictions sampled.
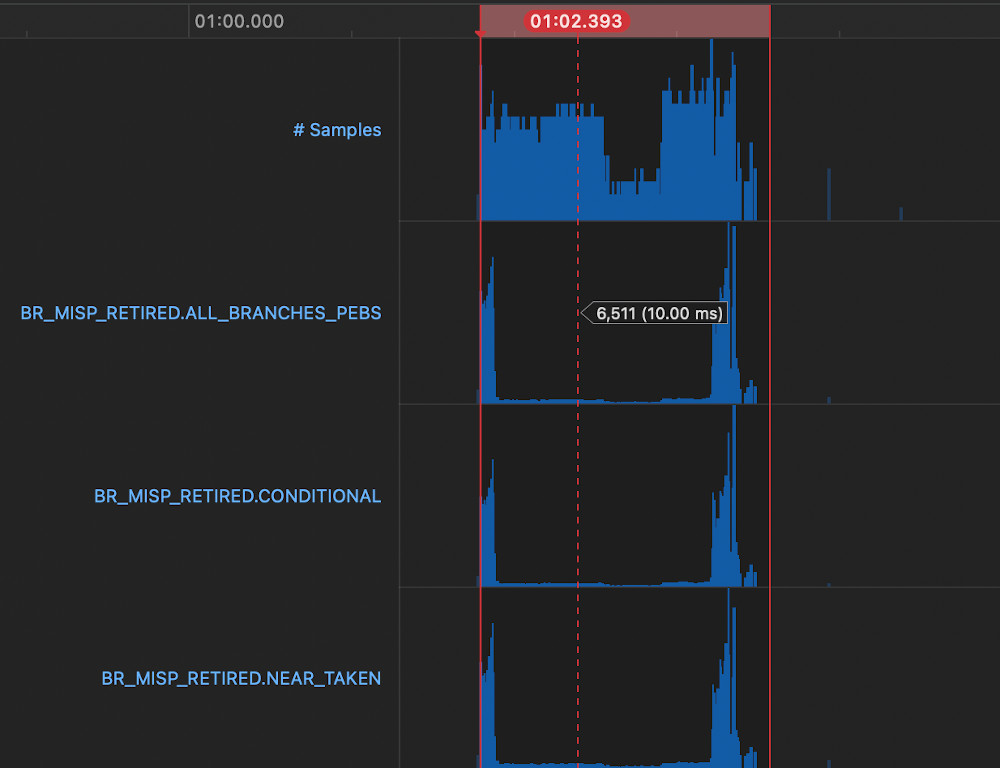
Whereas with the change picking a representative sample shows 6511 branch mispredictions sampled, which roughly correlates with the difference in latency from the change.
I had been profiling emacs using Instruments awhile ago and had observed that the majority of garbage collection time in my use cases tended to be insweep conses. I increasedBLOCK ALIGNin response to that because 1024 is a pretty small number for processors nowadays, and observed that my garbage collection time perceptibly decreased. I had suspected that it could be caused by branch mispredictions from iterating the cons block linked list, but I was not confident in that assertion without direct evidence.
Recently, I learned that CPU Performance Counters are available in Instruments without having to recompile emacs with additional flags and that one of the counters counted branch mispredictions. With that newly acquired knowledge, I decided to run this experiment to confirm that conjecture.
I implemented adefault.nixfor my fork of emacs optimized for newer versions of MacOS. The build is impure in that it relies directly on the host sdks from xcode instead of relying on the end user to store a xcode zip in a nix store. Now a full working Emacs build optimized for MacOS with dependency resolution and the homebrew-emacs-plus patches is available by running the following command at the repo root:
- nix-build
Because of that impurity, the rest of the build is reproducible since the rest of the dependency closure is pure. This avoids most of the tradeoffs with using nix on macos to build Emacs.
Also, it overrides the deployment target so that the build can benefit from the newer MacOS windowing features.
Special thanks to @jimeh for build-emacs-for-macos. That was my preferred way to build emacs prior to this implementation.
Sometimes while debugging nix packages, you need to know what a value is at runtime. NixPkgs provides the function traceValto trace a value at a specific point of the execution.
TraceVal takes one argument, the value that will be traced, and returns the value as is without modification. It can always be accessed from the nixpkgs set like:
- let pkgs = import <nixpkgs> {};
- in (pkgs.lib.debug.traceVal pkgs.emacs)
Since nix execution is lazy, the call to traceVal must be part of the dependency graph of the execution. The following example would not be evaluated, since it is not referenced by the derivation:
- let pkgs = import <nixpkgs> {};
- not_referenced = (pkgs.lib.debug.traceVal pkgs.emacs);
- in pkgs.emacs
Whereas the following example would be evaluated:
- let pkgs = import <nixpkgs> {};
- referenced = (pkgs.lib.debug.traceVal "OVERRIDE_NAME");
- in pkgs.emacs.overrideAttrs (oldAttrs: { name = referenced; } )
nixpkgs.lib.debugprovides a bunch of additional tracing functions that are worth looking into further.
Emacs For MacOS sometimes has frame hangs when there are a lot of changes occurring at once. This happens because there is IOSurface contention in the current implementation.
The implementation uses IOSurfaces to achieve double buffering. It swaps out an IOSurface which is used asynchronously by a CALayer to render to the window. Currently, it uses two IOSurfaces total: the one that's currently displayed and the one that's being used to render the change.
Having only two IOSurfaces leads to a race condition. When neither buffer is free, the implementation uses the least recently used buffer. This can potentially lead to cascading IOSurface contention depending on the speed of redraws occurring, since one delay can lead to further delay. The cascade is not catastrophic because blocking the redraw loop slows down the rate of changes which allows the contention to cease.
The lock contention can be avoided by increasing IOSurface count from two to some number greater than 2. I arbitrarily set it to 16 for my own purposes, and anecdotally have observed a decrease in frame hangs at runtime.
The CALayer's opaque property defaults to NO. There are benefits to the performance of compositing operations by setting it to YES since the compositor no longer has to be concerned with transparent values. It is probably a mild performance benefit but has no negative impact in my usage since I do not use transparent frames.
- (obs-dsl
- (scene "Main"
- (start-recording)
- (microphone "mic")
- (run-at-time 3 nil (lambda () (stop-recording)))
- (browser "website" "https://tdodge.consulting" :width 1920 :height 1080)))
I have been working withOBSrecently, was looking for ways to automate it via emacs, and noticed a dearth of elisp packages related to this. To remedy this, here is obs-dsl.el.
obs-dsl.el is defined with the intent of being the source of truth for the current obs configuration.
The prior code block shows an example configuration via the dsl. It defines a scene called Main that contains a microphone named "mic" and a browser named "website" displaying tdodge.consulting. It records for 3 seconds and then stops.
A neat aspect of having this be a dsl is that it integrates cleanly with arbitrary emacs lisp. Below is an example of using elisp to run a count-up timer with a count-down timer to send the right message in OBS.
- (obs-dsl
- (scene "Main"
- (start-recording)
- (microphone "mic")
- (let ((count-down-id "count-up")
- (count-up-id "count-down")
- (count-down 100)
- (counter 0)
- (timer nil))
- (text count-up-id "0" :x 0)
- (text count-down-id "0" :x 500)
- (setq timer (run-at-time nil 1 (lambda ()
- (condition-case err
- (progn
- (set-text count-up-id (number-to-string (setq counter (1+ counter))))
- (set-text count-down-id (number-to-string (setq count-down (1- count-down)))))
- (error (cancel-timer timer)))))))))
Obs-dsl.el still needs additional work before it will be complete. OBS needs an additional websocket API so that obs-dsl.el can get the window list and process list from the destination computer so that it can support screen capture. Alternatively, the the existing APIs could support looking up based on name instead of relying on host-specific IDs.
The diff check could be better than it currently is, which would get rid of some flicker effects.
Eshell is an excellent package for emacs. However, it has the appearance of being slow in comparison to other shells. Turns, out this is not eshell's fault, but a limitation in how emacs processes subprocess output in conjunction with the default STDOUT buffer sizes for PTY processes (On MacOS this maxes out at1024 bytes) This becomes more of an issue because emacs handles subprocess output in the event loop in which it handles all other user input.
In a change that I made to my fork of emacs, I added a background thread that continuously handles buffering subprocess output. This has the benefit of ensuring that the subprocess output is consumed as soon as it is available in STDOUT, which minimizes the amount of time that the subprocess blocks waiting for emacs to consume its output. This also makes it so that the strings passed to the subprocess filter can be larger than 1024 bytes because multiple reads can happen in the time between event loop evaluations.
For reference, on my machine running UnrealHeaderTool without the change would take around 70 seconds to complete because of the 1024 byte buffer bottleneck.
Running it with the change takes 3 seconds, which is aproximately a 95.7% reduction in latency.
Similarly, running sourcekitten complete goes from 7.334 seconds to 0.344 seconds, which is aproximately a 95.3% reduction in latency.
RED The subprocess is blocked waiting for STDOUT to be read
YELLOW The subprocess is writing to STDOUT
BLUE Emacs is doing something other than reading subprocess output
GREEN Emacs is processing subprocess output including other processes
An emacs subprocess can either use a pipe or a PTY to communicate with emacs. If you're only consuming stdout you want to use a pipe because the STDOUT buffer can be much larger. However, if you also need to write to STDIN, you will need to use a PTY. All processes that run inside eshell use a PTY so that the process can accept user input.
On MacOS, this has the effect of routing all subprocess output through a 1024 byte bottleneck. Each time the 1024 byte buffer is consumed by emacs, emacs decodes it according to the subprocess's locale, and then passes it to the subprocess's filter, which handles displaying it in the eshell buffer. This causes a number of issues:
The commit adds a background thread for processing output from subprocesses continually. It tries to behave similarly to read() as an interface to minimize the amount of changes necessary in process.c. This abstraction has a few leaks in that waiting_for_process_output can no longer rely on the ready states of the fds when computing the fd mask.
To mitigate this, an internal file descriptor is added so that the background thread can notify the main thread when the process output is available. Similarly, another file descriptor is used to communicate back to the background output producer thread when it stops because the output buffers are full.
With this change, using eshell is a lot closer to indistinguishable from other terminals which is impressive considering how much more extensible it is in respect to consuming output. In conjunction with my package org-runbook.el, Eshell is the best terminal experience available today.
- (defun eshell-output-filter-debug-advice (process string)
- "Remove me with with C-x C-e in Help on the following form:
- `(advice-remove
- ''eshell-output-filter
- #''eshell-output-filter-debug-advice)' "
- (message "Output Filter Buffer Size: %d"
- (length string)))
- (advice-add 'eshell-output-filter
- :before #'eshell-output-filter-debug-advice)
Output Filter Buffer Size: 3565 Output Filter Buffer Size: 182778 Output Filter Buffer Size: 4
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1020
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1020
Output Filter Buffer Size: 1022
Output Filter Buffer Size: 1020
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1020
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1022
Output Filter Buffer Size: 1022
Output Filter Buffer Size: 1022
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1022
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1020
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1020
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1022
Output Filter Buffer Size: 1022
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1022
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1020
Output Filter Buffer Size: 1022
Output Filter Buffer Size: 1022
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1022
Output Filter Buffer Size: 1016
Output Filter Buffer Size: 1022
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1016
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1022
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1016
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1022
Output Filter Buffer Size: 1020
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1020
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1022
Output Filter Buffer Size: 1022
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1018
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1022
Output Filter Buffer Size: 1020
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1022
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1020
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1022
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 1024
Output Filter Buffer Size: 87
Output Filter Buffer Size: 11
Output Filter Buffer Size: 14
An Augmented Reality Beer Pong iOS Game Released in October 2019.
A custom search page built on top of OpenSearch.
An Org babel extension for Chat Assistant APIs such as ChatGPT
A DSL for controlling OBS from Emacs for live productions.
A mode that allows editing files in place for use with counsel-ag, counsel-rg, counsel-git-grep, counsel-ack, and counsel-grep.
A library for executing runbooks in org format.
A Queue for scheduling and running shell commands in emacs sequentially.
A company backend for autocompleting tailwindcss classes.
An transformer for using copilot to sort autocomplete results from other company backends.
A company backend for getting results from eglot servers asynchronously.
Tyler is my long-time friend and colleague from our time consulting together while attending NCSU, until afterwards working together at Amazon. Simply put: his work is meticulous and fast, and he's one of the best developers I know in the industry. If you are considering his consultancy, starting your code base with best practices and avoiding troublesome vendor lock-in is a must-have. I cannot recommend T Dodge Consulting LLC enough for your consulting needs.
- Brandon Prime
I’ve know Tyler for years and he’s the best developer I’ve ever met! We launched an Augmented Reality game together called AR Pong in the iOS App Store and he coded the whole thing by himself. Don’t hesitate to bring him on your project! You will not regret it.
- Ty Moss
Tyler Dodge has a unique talent for lateral thinking and unconventional approaches. His understanding of the context and background inherent in a given project leads to the sort of innovative idea you just can't achieve in a larger, more homogenized shop.
- Leighton Cline